node.js的异步IO机制
概念理解
单线程、异步非阻塞I/O、事件驱动 是Node.js的三大闪光点。其中,理解异步非阻塞I/O模型是学习node过程中的一大难点。
什么是I/O
I/O在计算机中指Input/Output,也就是输入和输出,分为I/O设备和I/O接口两个部分。
- I/O接口是CPU和I/O设备之间交换信息的媒介和桥梁。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等。
- 现代计算机系统中配置了大量的外围设备,即I/O设备。通常进行如下分类:
- 字符设备,又叫做人机交互设备,例如,键盘和显示器为一体的字符终端、打印机、鼠标等。
- 块设备,又叫外部存储器,用户通过这些设备实现程序和数据的长期保存,如磁盘、光盘等。
- 网络通信设备。这类设备主要有网卡、调制解调器等,主要用于与远程设备的通信。
同步与异步I/O
由于CPU和内存的速度远远高于外设的速度,所以,在I/O编程中,就存在速度严重不匹配的问题。比如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可能需要10秒,怎么办呢?有两种办法:
- 同步I/O:CPU等待,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行。
- 异步I/O:CPU不等待,后续代码可以立刻接着执行。
- 实现方式1:主动轮询异步调用的结果。
- 实现方式2:被调用方通过callback来通知调用方调用结果。
同步和异步是一种通信机制,涉及到调用方和被调用方,关注的是I/O操作的执行过程及结果的返回方式,不同点在于双方在这两个方面的行为方式。
阻塞与非阻塞I/O
- 阻塞I/O:调用结果返回之前,该执行线程会被挂起,不释放CPU执行权,线程不能做其它事情,只有等到调用结果返回了,才能接着往下执行
- 非阻塞I/O:在没有获取调用结果时,线程可以往下执行,而不是等待。
- 如果是同步的,会通过轮询的方式检查有没有调用结果返回;
- 如果是异步的,会通知回调。
阻塞和非阻塞是一种调用机制,只涉及到调用方,关注的是I/O操作的执行状态,不同点在于请求I/O操作后,针对I/O操作的状态,调用方的行为方式。
举个🌰
故事:老张烧开水。
出场人物:老张,普通水壶,会响的水壶。
- 老张把水壶放到火上,立等水开。(同步阻塞)
- 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
- 老张买了把会响笛的水壶。水开之后能发出嘀~~~~的噪音。老张把响水壶放火上,立等水开。(异步阻塞)
- 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,电视放什么他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
Node.js与异步
Node为什么要选择异步?
1、前提条件:JavaScript是单线程的
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
2、从用户体验角度讲,异步I/O可以消除UI阻塞,快速响应资源
- JavaScript是单线程的,它与UI渲染共用一个线程。所以在JavaScript执行的时候,UI渲染将处于停顿的状态,用户体验较差。而异步请求可以在下载资源的时候,JavaScript和UI渲染都同时执行,消除UI阻塞,降低响应资源需要的时间开销。
- 假如一个资源来自两个不同位置的数据的返回,第一个资源需要M毫秒的耗时,第二个资源需要N毫秒的耗时。
- 当采用同步的方式,总耗时为(M+N)毫秒。
- 当采用异步的方式,总耗时为max(M,N)毫秒。
3、从资源分配角度讲,异步I/O可以让单线程远离阻塞,以更好地利用CPU
- 假设业务线上有一组互不相关的任务需要完成,现行的主流方法有以下两种:
- 单线程同步执行:会阻塞I/O导致硬件资源和CPU得不到更优的使用。
- 多线程并发执行:会出现死锁、状态同步等问题。
- Node的解决方案
- 利用单线程远离多线程的死锁、状态同步等问题。
- 利用异步I/O,让单线程远离阻塞,更好的利CPU。
Node如何实现异步I/O?
事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素。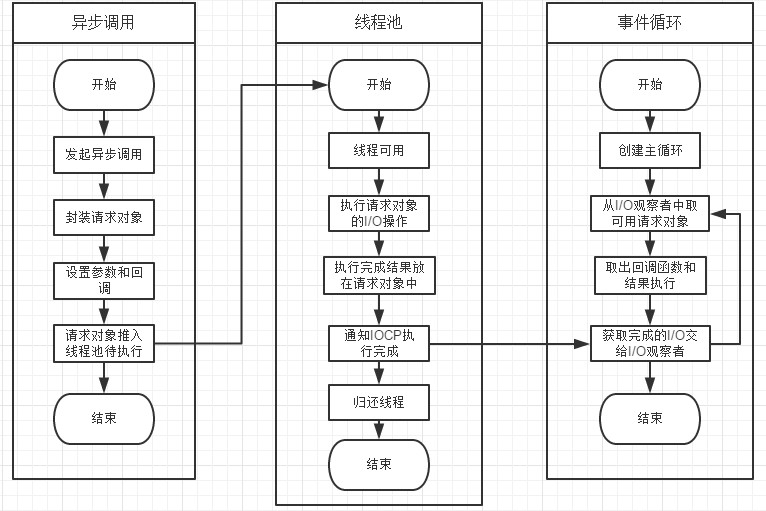
整个实现过程大概更可以描述为:
- 发起异步请求之后将请求进行封装,封装为请求对象,对请求对象设置参数和回调函数并将请求对象放入线程池,线程池中检查是否有可用线程,当线程可用时执行请求对象的I/O操作,并将执行完成的结果放入请求对象中,通知IOCP调用完成并获取完成的I/O交给I/O观察者。
- 在libuv中创建主循环开始事件循环,主循环从I/O观察者中取出可用的请求对象,在请求对象中取出回调函数和I/O结果并调用回调函数。
名词解析
观察者:事件循环判断是否有事件待执行,就是通过询问观察者,观察者不会主动通知进程,而是进程询问时才返回结果。
事件循环是生产者/消费者模型。异步I/O和网络请求是事件的生产者,这些事件被输送到观察者,事件循环是消费者,从观察者这里取出事件处理。观察者就相当于模型中的缓冲区,生产者不断产生事件放到缓冲区,而消费者从缓冲区里取出事件进行消费。
libuv:libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。它是Node.js实现异步的核心。
请求对象:从JavaScript发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,叫做请求对象。从JavaScript传入的参数和当前方法都被封装在这个请求对象中,其中回调函数则被设置在这个对象的oncomplete_sym属性上。
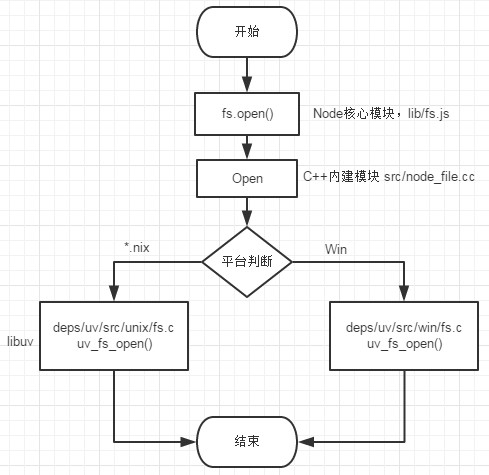
假设fs.open(),根据指定路径和参数打开文件。在JS发起调用后,JS调用Node的核心模块(lib/fs.js),核心模块调用C++内建模块(node_file.cc),內建模块通过libuv判断平台(是*nix还是win)并进行系统调用。在进行系统调用时,从JS层传入的方法和参数都被封装在一个请求对象FSReqWrap中,请求对象被放在线程池中等待执行。JS立即返回继续下面的操作。I/O线程池:在Node中,JS是在单线程中执行的,但是内部完成I/O工作的另有线程池,使用一个主进程和多个I/O线程来模拟异步I/O。当主线程发起I/O调用时,I/O操作会被放在I/O线程来执行,主线程继续执行下面的任务。I/O操作不管是否阻塞,都不会影响JS执行线程的执行。在I/O线程完成操作后会带着数据通知主线程发起回调。
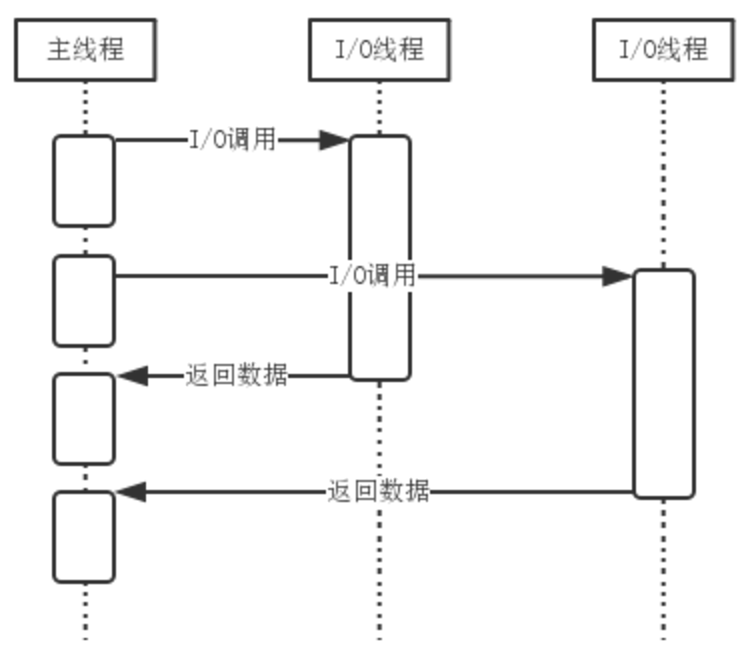
因此,Node.js 的单线程仅仅是指 JavaScript 运行在单线程中,而并非 Node.js 是单线程。事件队列:Node.js 在主线程里维护了一个事件队列,当接到请求后,就将该请求作为一个事件放入这个队列中,然后继续接收其他请求。当主线程空闲时(没有请求接入时),就开始循环事件队列,检查队列中是否有要处理的事件,这时要分两种情况:如果是非 I/O 任务,就亲自处理,并通过回调函数返回到上层调用;如果是 I/O 任务,就从 线程池 中拿出一个线程来处理这个事件,并指定回调函数,然后继续循环队列中的其他事件。
事件循环 (Event Loop):在进程启动时,Node会创建一个类似于While(true)的循环,每执行一次循环体的过程称为Tick。每个Tick过程中观察者会查看是否有事件需要处理,如果有就取出事件及其相关的回调函数并执行。然后进入下一个Tick。如果没有事件处理,就退出进程。
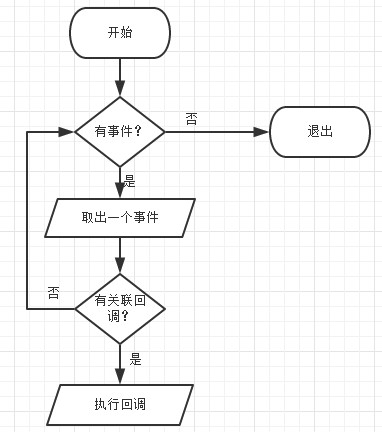
执行回调:I/O执行结束后,会将结果通知IOCP(windows下,linux下epoll),并将线程归还线程池。使用事件循环的I/O观察者,如果有已经执行完的I/O,则将请求对象加入I/O观察者队列中,事件循环再Tick过程中,检测到有I/O观察者,则取出其中的请求对象,再取出请求对象中的回调函数执行。
代码模拟
Node.js 实现异步的核心是事件,也就是说,它把每一个任务都当成 事件 来处理,然后通过 Event Loop 模拟了异步的效果,为了更具体、更清晰的理解和接受这个事实,下面我们用伪代码来描述一下其工作原理 。
【1】定义事件队列
既然是队列,那就是一个先进先出 (FIFO) 的数据结构,我们用JS数组来描述,如下:
1 | /** |
我们利用数组来模拟队列结构:数组的第一个元素是队列的头部,数组的最后一个元素是队列的尾部,push() 就是在队列尾部插入一个元素,shift() 就是从队列头部弹出一个元素。这样就实现了一个简单的事件队列。
【2】定义接收请求入口
每一个请求都会被拦截并进入处理函数,如下所示:
1 | /** |
这个函数就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
1 | /** |
主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理I/O操作,比如读取数据库:
1 | /** |
当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
缺陷
Node.js通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。
但不是所有的任务都是I/O密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密、数据压缩和解压,这时Node.js就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着。
在事件队列中,如果前面的CPU计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多CPU或多核的,而Node.js只有一个Event Loop,也就是只占用一个CPU内核,当Node.js被CPU密集型任务占用,导致其他任务被阻塞时,却还有CPU内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
总结
- Nodejs实际上只是应用程序层面JavaScript单线程执行,真正I/O操作、网络请求、底层API调用都是多线程执行。
- 事件循环是Node异步I/O实现的核心,Node通过事件驱动的方式处理请求,使得其无须为每个请求创建额外的线程,省掉了创建和销毁线程的开销。同时也因为线程数较少,不受线程上下文切换的影响,维持了Node的高性能。
- Nodejs具备单线程执行应用程序、异步非阻塞I/O的特点,因此适用于I/O密集型场景,而并不擅长于CPU计算密集型场景。
参考文档
从浏览器多进程到JS单线程,JS运行机制最全面的一次梳理
单线程NodeJS的异步I/O
[读书笔记]深入浅出NodeJS——Node中的异步I/O
Node.js 事件循环机制
JS/NodeJS中的异步任务与事件环
深入浅出node.js